Thanks to Micki Kauffman‘s gracious invitation to participate in Text Analysis, Visualization, and Historical Interpretation I am giving a paper Using Big Data to Answer Historiographical Questions; or, Can Digital History Fulfill the Promise of Social History? at the American Historical Association meetings. I want to also acknowledge Chris Forster who generously aided me with some xml file issues, Shawn Graham, Mitch Fraas and John Swain who kindly worked with my data for Gephi. Finally, Micki Kauffman helped me scrape source material yet again. [note there was an amazing back channel during the panel that was storified but comments here are also welcome]
Although I must admit to not a little disappointment when I first spied our session located on the last day of the conference, I have discovered that one of the benefits of presenting on the last day is the ability to put into practice immediately all the wonderful ideas gleaned from other conference presenters.
Inspired, as always, by Jesse Stommel’s my presentation in a single tweet
My slides for Digital Pedagogy Lightning Round are a single tweet. https://t.co/Dj0lKgm36K #AHA2015 #s95
— Jesse Stommel (@Jessifer) January 3, 2015
I offer the tweet that launched a thousand pictures
@jacquehettel @heatherfro my @gephi pictures feel not pretty enough, I have visualization envy — Michelle Moravec (@ProfessMoravec) September 28, 2013
I come to you from the land where most historians skip all the figures and engage in what Johanna Drucker describes as “the denigration of vision” and the “visualization as interpretation” she calls for remains something most historians view with a side eye. [When I joked with another historian about my presentation title today should really be how to convince historians that numbers are evidence, she told me of a study about the decline of quantitative history – see Steven Ruggles on topic- purportedly based on the decrease in papers of one phrase: “table 1.”]
How then can we as historians producing digitally make our arguments persuasively? This question cuts to the heart of my interest in working digitally. Raised on the new social history, I want to tell the histories of women’s liberation not just through the well known names, or short lived groups in large metropolitan areas, but the histories of the hundreds of thousands of women across the United States whose lives were transformed by the movement. Some twenty years after I started as an oral historian sitting across the table from one woman, I find myself using a computer to read thousands of articles written by participants in the movement. This text mining is techno-optimism at its finest, hoping that by removing the authorial selection bias that I’ll find new or different histories, yet to shift historiographies I have to engage large audiences of historians, and historians not necessarily digitally conversant or familiar with my methodologies.
Which brings me to one of the questions this panel addresses – To what extent must historians explicitly confront their methodological relationship to other disciplines? I write histories using methods borrowed from corpus linguistics that are statistically based. This process involves quantitative claims, based on statistical analysis, and qualitative, involving interpretations.
If statistical analysis is my historical evidence how do I persuade scholars accustomed to textual proof?
Since I can’t turn numbers into words, I’ve been searching for a way to make them into pictures, lots and lots of different kinds of pictures designed to visualize for historians the statistical relationship between words and to persuade my colleagues that these visualizations should change how we think historiographically. That brings me to the second question posed to our panel Can design and improved visual literacy effectively bridge the gap between statistical inference and historical interpretation?
In preparing a talk for the Berkshire Conference of Women Historians this spring, I struggled with how best to not only visualize my corpus linguistics data, but to persuade historians to pay attention. I knew I needed a gee whiz! data viz, so using Jacqueline Hettel’s methodology, I scraped Google books citation and subject metadata to show how a tight historical analysis had been adopted widely and applied beyond its temporal bounds.
which data viz do we like better for showing “discipline creep” of Echols from google book metadata pic.twitter.com/CXAzT9c4BX
— Michelle Moravec (@ProfessMoravec) May 13, 2014
and then some from JSTOR.
. @jstor DFR 4 “discipline creep”Echols’ historically specific “cultural feminism” 137 articles 1989-2013 cite her pic.twitter.com/QpPBUFRqNL — Michelle Moravec (@ProfessMoravec) May 13, 2014
and then this
1 @densitydesign makes FAB interface & r too nice when U are less than on top of things 2. HOW PRETTY IS THIS VIZ pic.twitter.com/5Yxj7pEvG1 — Michelle Moravec (@ProfessMoravec) May 13, 2014
although I finally just used this because it seemed to make the point.

Although I spent an ridiculous amount of time on visualizations I never used, the bigger challenges lay in introducing inter-related but distinctive corpus linguistic concepts to use as evidence. Clusters, patterns of word occurrences (like cultural feminism) proved easy enough to do in tables, as corpus linguists do. Collocations, word that co-occur within a span of texts (i.e. feminism must be political and cultural), however plagued me to no end. Collocates provide some of the most valuable evidence from corpus linguistics, but the concept is hard to explain to historians because collocates are based on statistics that may be unfamiliar and collocates do not form easily recognized patterns.My data viz envy lead me to experiment in all sorts of waysto visualize collocation, such as this odd duck done with Gephi on Carolee Schneemann’s correspondence.
@jacquehettel @heatherfro collocates of like (82, 26= like a!) @Gephi pic.twitter.com/ol5j10HOzv
— Michelle Moravec (@ProfessMoravec) September 28, 2013
and in other ill-fated ways, as in my presentation at the Berkshires, based on feminist periodicals provided by JSTOR.
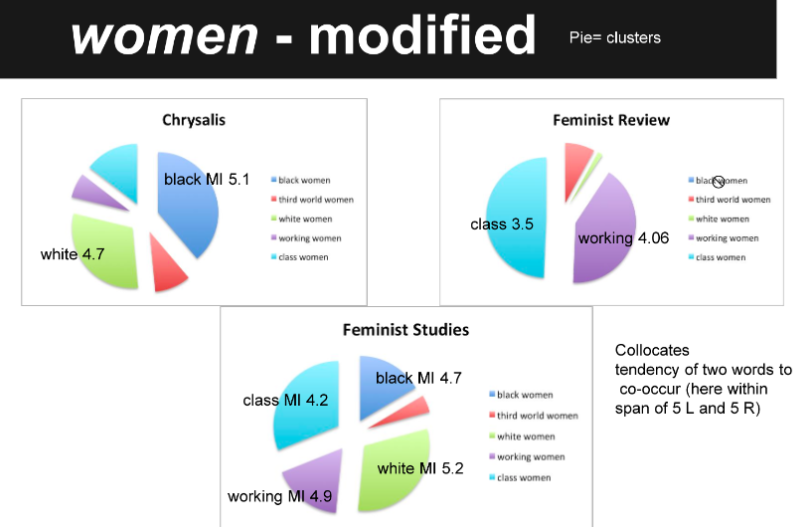
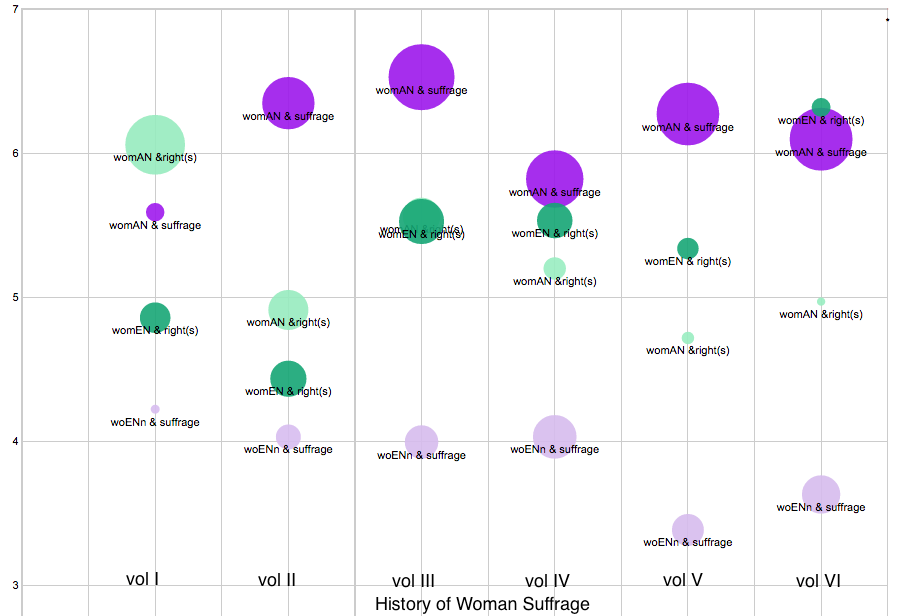
I just finished a digital project reinterpreting suffrage history working with Thomas Dublin at Women and Social Movements. I played around again with ways to viz collocates, and I loved this one, which I explained during a talk on the project, but ultimately rejected as too complicated for readers who wouldn’t have me standing there to explain it all.
The piece I ended up publishing,“Under this name she is fitly described”: A Digital History of Gender in the History of Woman Suffrage has 12 figures, all line or bar graphs and tables that I made in excel. Sometimes you need the thousands words for the text and not to explain a picture.
I’ve obviously been a little disingenuous in this talk to make my point. Making good on the promise of social history digitally does involve complex visualizations that will require the historian reader to do some work to understand. No where is that clearer than in the case of network analysis. To get at the contributions of the thousands of women involved in the movement, I’ve also experimented with network analysis visualizations based on NER extractions from feminist periodicals. I worked with 26000 names pulled out of four periodicals ranging from strictly academic Signs to activist Off Our Backs in hopes of analyzing communities. The process has been exhilarating and frustrating. In the recognizable names that appear in all four periodicals, Adrienne Rich tops the list, not entirely unexpected, although perhaps not consistent with her status in the historiography, but also Elaine Reuben, who I will admit to not knowing at all. Yesterday during the digital drop in hours, lots of the experts had a go at my data (thanks Abby Mullen and Kalani Craig), and we got some great gee whiz results.

Clearly, I am still a far way off from the visualization that would convince historians to pay attention to Elaine Reuben, who appears along with Rich at the center. However, I am inspired by other historians working digitally, particularly those on this panel, to find ways to communicate to the historians I need to persuade.
However, I also see a need for historians who are working digitally to produce new historical interpretations to find ways to make their work clear to one another. Sometimes it feels like if work is not presented in the latest bleeding edge tool it may pass un-noticed. This may be a marker of the success of digital history in attaining some sort of critical mass (simply producing a new historical interpretation digitally no longer guarantees everyone will rush to check it out), but also means there are sometimes jarringly disconsonant experiences, such as I have had at this conference.
Great post. This is really, really interesting. First, I find it fascinating that there is a ‘decline of quantitative history’ since many of our cousins in the social sciences seem to embrace quantitative data (presumably because it appears more scientific than qualitative approaches). Second, it echoes of earlier challenges 19th century scholars who sought to represent big data to make arguments. The explorer Alexander von Humboldt, for example, first introduced “isothermal lines” in 1805 to show regions of similar temperature across the spacial lines of a map. This was really the beginning of thematic mapping and Humboldt had to explain what he was doing with copious instructions to his readers. Today, we understand the isothermal lines of a weather map without even thinking about it. I wonder if one or more of the visualizations you present will become standard features of historical argument going forward — just reading this makes me want to figure out how to use Gephi. Sorry I didn’t get a chance to see your talk at AHA :(. Good luck with your work!